#代码,在运行之前请安装Python和相应的Python库
import requests
import os
from urllib.parse import urlparse
from datetime import datetime
import tkinter as tk
from tkinter import ttk
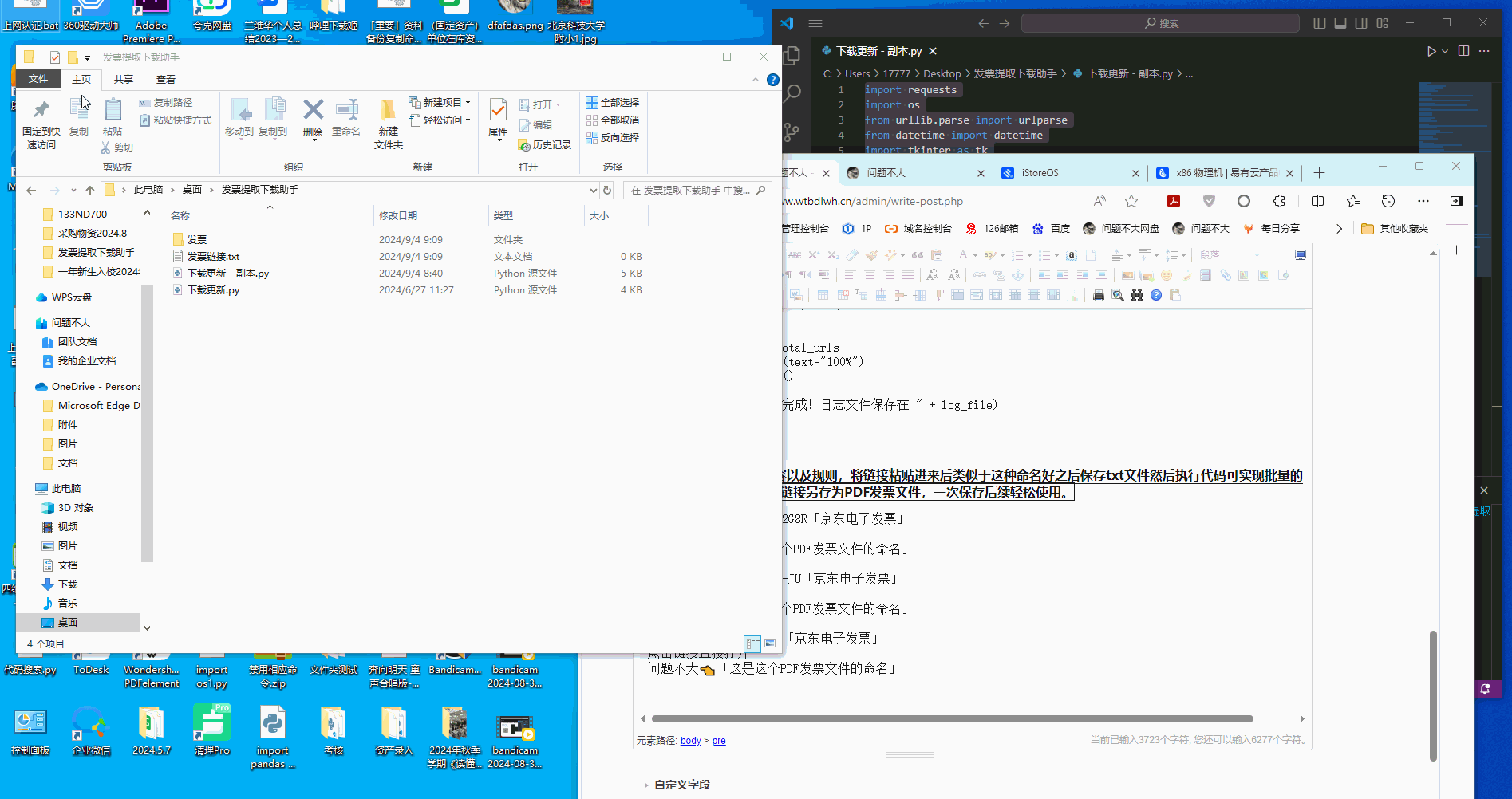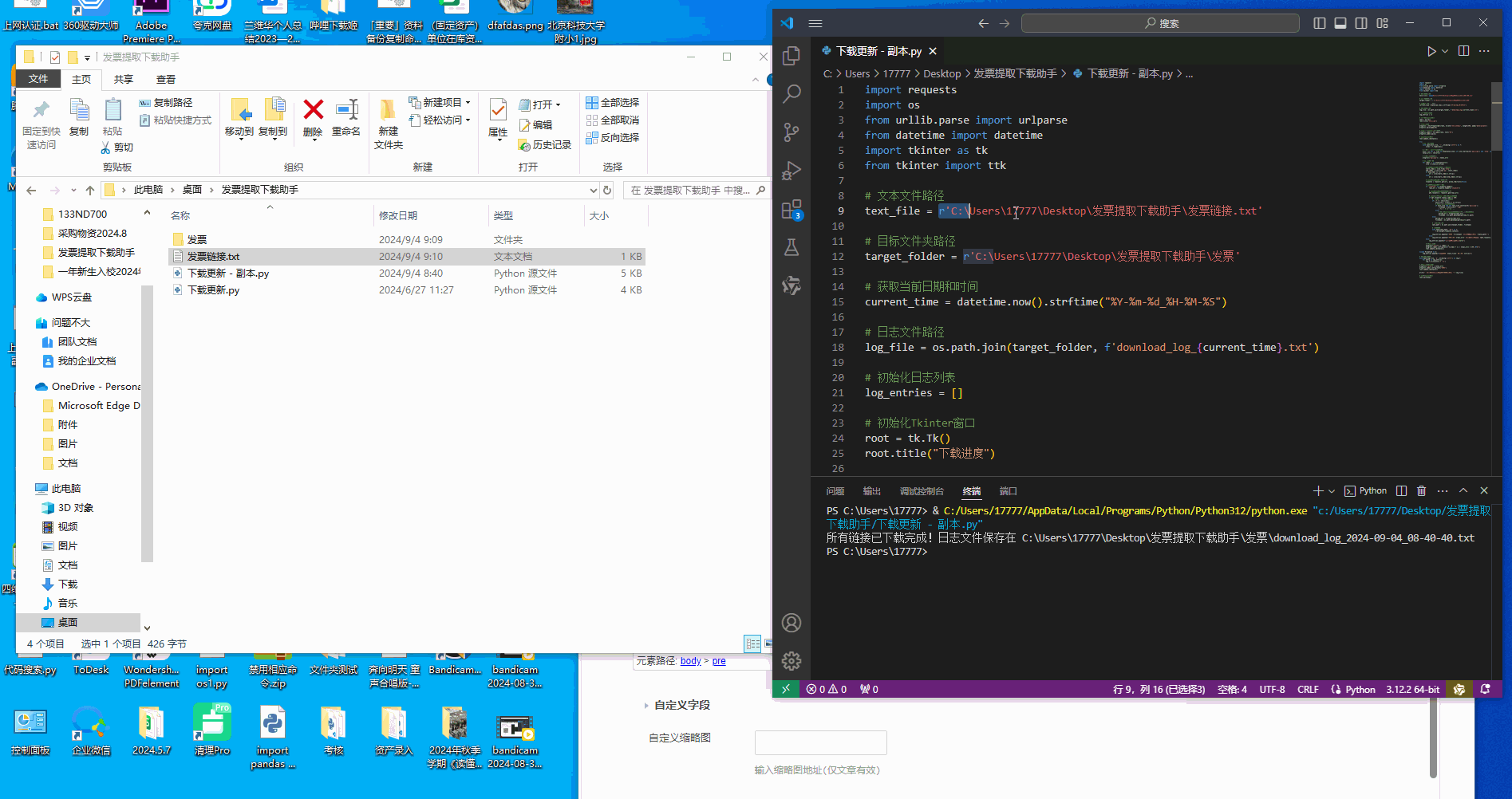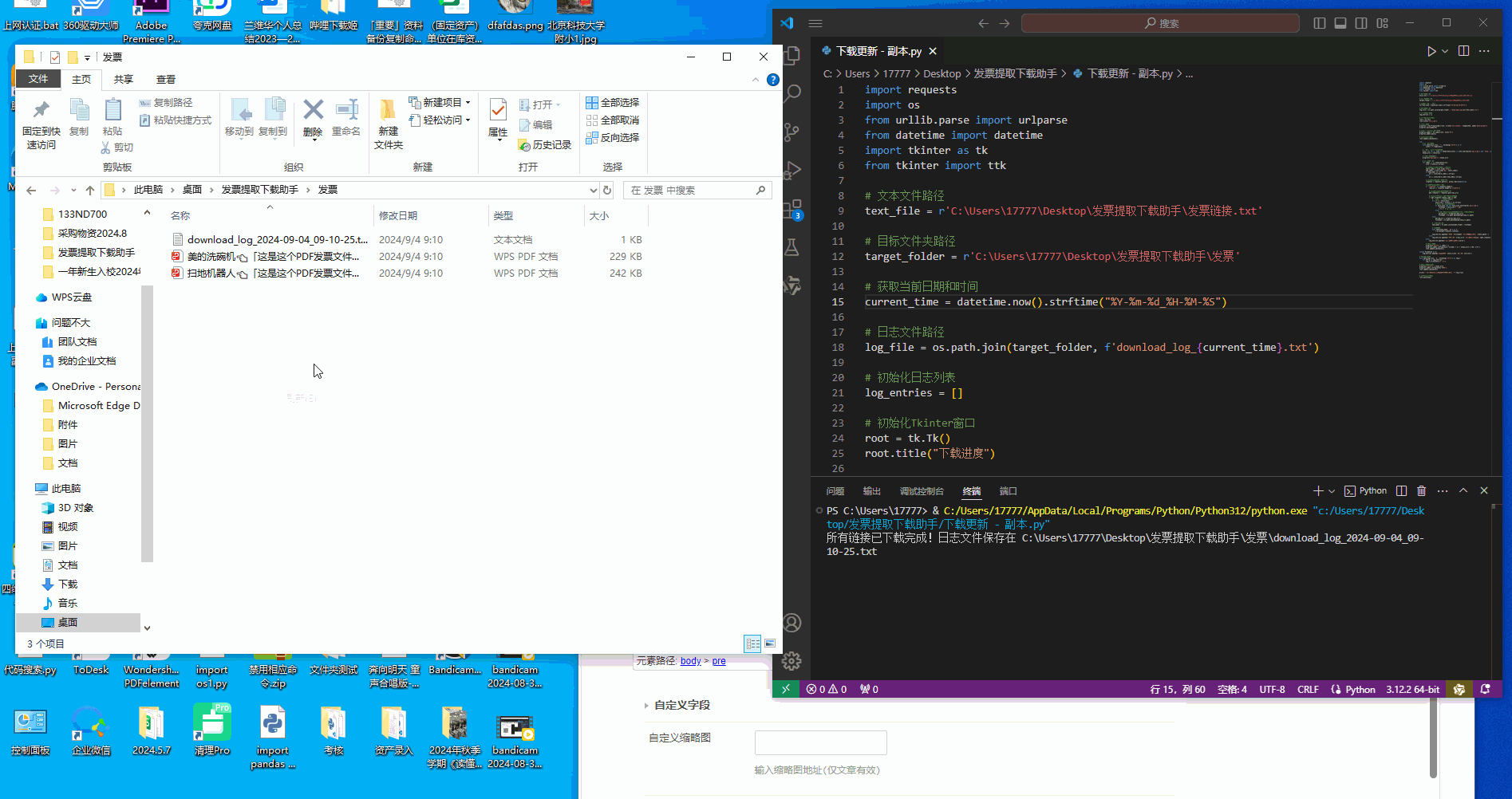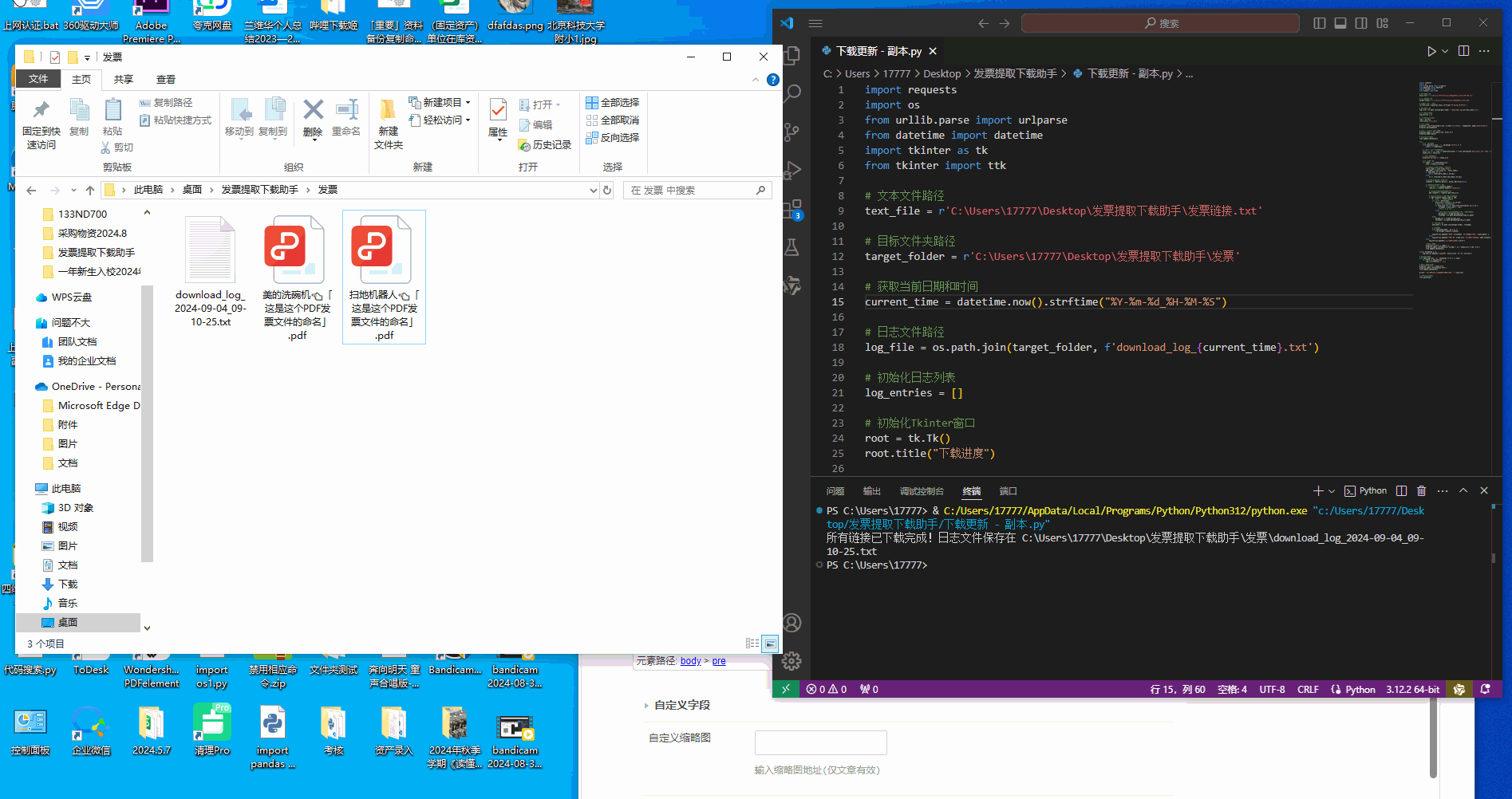
# 文本文件路径,需要在电脑新建一个文件夹然后创建一个txt类型的文件,将发票链接进行批量粘贴并进行发票名称的命名。
text_file = r'C:\Users\17777\Desktop\发票提取下载助手\发票链接.txt'
# 目标文件夹路径
target_folder = r'C:\Users\17777\Desktop\发票提取下载助手\发票'
# 获取当前日期和时间
current_time = datetime.now().strftime("%Y-%m-%d_%H-%M-%S")
# 日志文件路径
log_file = os.path.join(target_folder, f'download_log_{current_time}.txt')
# 初始化日志列表
log_entries = []
# 初始化Tkinter窗口
root = tk.Tk()
root.title("下载进度")
# 创建进度条
progress = ttk.Progressbar(root, orient="horizontal", length=300, mode="determinate")
progress.pack(pady=20)
# 创建标签以显示进度百分比
progress_label = tk.Label(root, text="0%")
progress_label.pack()
# 刷新Tkinter窗口
root.update_idletasks()
try:
# 打开文本文件
with open(text_file, 'r', encoding='utf-8') as f:
lines = f.readlines()
# 过滤出所有包含有效URL的行
urls = [i for i, line in enumerate(lines) if line.startswith('【京东】') and 'http' in line]
total_urls = len(urls)
# 设置进度条最大值
progress["maximum"] = total_urls
# 逐行读取链接
for index, i in enumerate(urls):
line = lines[i].strip()
# 提取URL,去除额外的格式化信息
start_index = line.find('http')
end_index = line.find('」', start_index)
if end_index == -1:
url = line[start_index:].strip()
else:
url = line[start_index:end_index].strip()
# 发送GET请求获取链接的内容
response = requests.get(url, allow_redirects=False)
# 获取重定向后的真实URL
if 'Location' in response.headers:
real_url = response.headers['Location']
# 发送GET请求获取PDF文件内容
pdf_response = requests.get(real_url)
# 确认响应状态码为200,表示请求成功
if pdf_response.status_code == 200:
# 检查下一行是否存在文件名
if i + 2 < len(lines):
next_line = lines[i + 2].strip()
# 判断是否是有效的文件名
if next_line and not next_line.startswith('【京东】'):
filename = next_line + ".pdf"
i += 2 # 跳过下一行
else:
# 如果没有找到有效的文件名,则使用默认文件名
parsed_url = urlparse(real_url)
filename = os.path.basename(parsed_url.path)
else:
parsed_url = urlparse(real_url)
filename = os.path.basename(parsed_url.path)
# 拼接保存路径
save_path = os.path.join(target_folder, filename)
# 保存文件
with open(save_path, 'wb') as f:
f.write(pdf_response.content)
log_entries.append(f"文件 '{filename}' 下载成功!保存在 '{save_path}'")
else:
log_entries.append(f"PDF链接 '{real_url}' 下载失败,状态码: {pdf_response.status_code}")
else:
log_entries.append(f"未找到重定向URL:{url}")
# 更新进度条
progress["value"] = index + 1
progress_label.config(text=f"{(index + 1) / total_urls * 100:.0f}%")
root.update_idletasks()
except Exception as e:
log_entries.append(f"处理文件 '{text_file}' 时出错: {str(e)}")
# 写入日志文件
with open(log_file, 'w', encoding='utf-8') as log_f:
for entry in log_entries:
log_f.write(entry + '\n')
# 更新进度条到100%
progress["value"] = total_urls
progress_label.config(text="100%")
root.update_idletasks()
print("所有链接已下载完成!日志文件保存在 " + log_file)
# 关闭Tkinter窗口
root.mainloop()以下是txt文件里面的内容以及规则,将链接粘贴进来后类似于这种命名好之后保存txt文件然后执行代码可实现批量的发票下载,无需单个进入链接另存为PDF发票文件,一次保存后续轻松使用。
【京东】https://3.cn/2G8R「京东电子发票」
点击链接直接打开
扫地机器人👈「这是这个PDF发票文件的命名」
【京东】https://3.cn/-JU「京东电子发票」
点击链接直接打开
美的洗碗机👈「这是这个PDF发票文件的命名」
【京东】https://3.c5t「京东电子发票」
点击链接直接打开
问题不大👈「这是这个PDF发票文件的命名」下面进行演示「因发票链接不方便对外展示因此进行了删减测试可能某些文件无法进行下载,完整链接没问题」